Transfer Learning Made Super Simple

Life Today
Deep learning has evolved in the past five years from an academic research domain, to being adopted, integrated and leveraged for new dimensions of productivity across multiple industries and use cases, such as medical imaging, surveillance, IoT, chatbots, robotic,s and many more. From NLP to computer vision, deep learning has been breaking the barriers of SOTA algorithms and providing results that were, otherwise, impossible to achieve.
A symbol of such maturity is the lowering of entry barriers into the domain. A field that once required skilled researchers, armed with domain expertise in deep learning, is now being democratized and made accessible to engineers and non-domain experts.
To achieve that level of commoditization, researchers and companies have released models such as the Yolo family, Faster RCNN (and Maskrcnn,) and the BERT NLP model. These very fast, very accurate models allow researchers to take the base model and tweak it to their own needs by either changing the backbone, tuning parameters or using transfer learning methods to repurpose the model.
One factor that almost always needs to be addressed is the input data (actually, the metadata) format. Currently there are countless semi-standard metadata formats. For example, take the COCO data format and the Pascal VOC format. Both of these datasets hold very similar metadata, but each employs a different file type (XML \ Json), file structure, and even label format. Companies and organizations often deploy their own self-created metadata formats, or use those of their respective 3p labeling contractors.
So what’s the upshot to this lack of standardization? Well, if researchers and data science teams want to use off-the-shelf products, they either need to modify the product’s repo’s source code to accommodate their metadata format, or, alternatively, to conform their in-house metadata format to that of the off-the-shelf repo’s. And then, they need to repeat the process, again and again, for each new open-source repo they want to integrate into their workflow and various datasets.
Yes, modifying these dataset formats is technically doable, but it’s time-consuming and error-prone – basically a pain. We’ve spoken to many data-scientists who have presented their work at NeurIPS, who report that they knowingly trained on clearly faulty datasets simply because it was too difficult to change the code to address the new dataset’s metadata format.
What Life Should Look Like
At Allegro AI, we believe that deep learning research and development should deploy as much of the best practice of standard software engineering as possible; it’s simply the best way to enable higher-quality core research without being hindered by the scaffolding around it. One key element of software engineering is the concept of encapsulation, wherein different pieces of code are encapsulated such that changing the internals of one part does not wreak havoc on the integration with other pieces.
Let’s apply this approach to compartmentalization into machine and deep learning: Models, code and datasets should be interchangeable as if they were Lego pieces. A given model should be able to work on any dataset of the type it was designed for (e.g., any given NLP model should work on any NLP dataset).
This is one of the key design principles in ClearML. In ClearML, switching between models and datasets is as easy as a couple of mouse clicks, or adding a few lines of code. This means that off-the-shelf open-source standard repos – once registered on ClearML – are now much more powerful, useful tools at the data scientists’ disposal. Transfer learning using SOTA repos becomes a snap!
Let’s See It In Action – Setting this all up
Let’s dive a little bit deeper and demonstrate this powerful abstraction and encapsulation capability with Yolo V3.
We took the Kitti 2D object detection repo, which uses the Yolo V3 object detection network, and made it data-agnostic; you can pipe in any data format and easily repurpose this powerful object detection repository.
We took this repo as a baseline and made simple modifications so it now gets data from the ClearML system instead of from offline files.
The first thing we did was to create an AllegroDataset class, which inherits from the KITTI2D class. The constructor gets a list that holds all of our frames (we’ll explain how we got it in just a second).
The class’ __getitem__ method stays the same, but we override the _read_label and _get_img_path methods:
The _get_img_path just gives us the frame from the frame list
def _get_img_path(self, index): return self.single_frames[index].get_local_source()
The _read_label method gets the annotations from the frame, converts them to Yolo’s expected format and…yeah, that’s about it 🙂
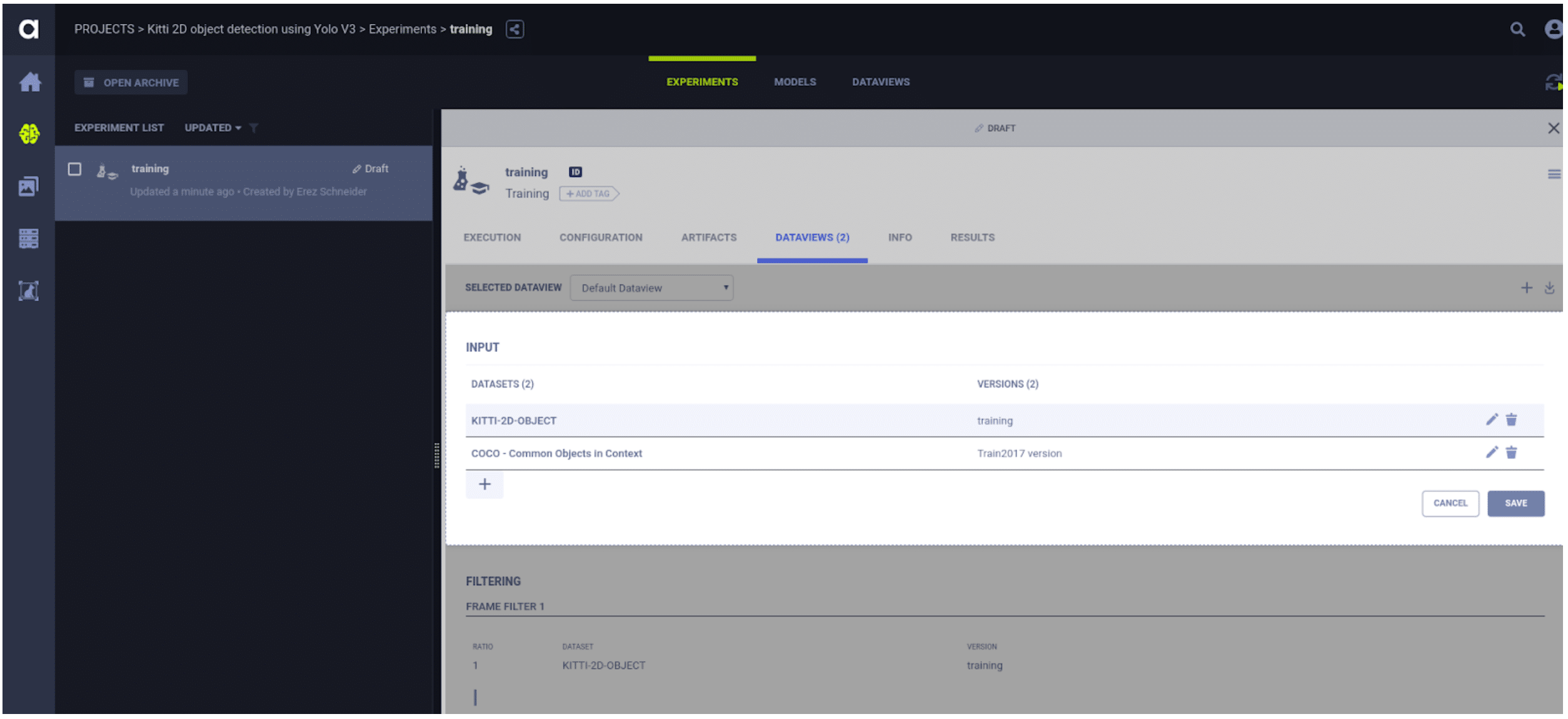
The last missing part is just getting the frame list, and this is done using ClearML’s dataview object.
Dataviews are viewports into datasets registered on ClearML. Think of them as powerful SQL queries on your data lake, with versioning on top and a few more tricks. You specify a dataset (or datasets), your specific version of choice and a query on top. Such as:
Give me only frames with at least two occluded vehicles, at least one pedestrian, taken after 20:00 on residential streets.
Viola! The dataview takes care of prefetching the exact data files needed for your training, ready to handoff to a dataloader.
dataview = DataView()
dataview.add_query(
dataset_name='KITTI 2D', version_name='training and validation', roi_query=['training'])
dataview.set_labels({
'Car': 0, 'Van': 1, 'Truck': 2, 'Pedestrian': 3, 'Person_sitting': 4, 'Cyclist': 5, 'Tram': 6, 'Misc': 7
})
train_list = dataview.to_list()
And that’s basically it!
Life’s Good
Your new SOTA repo is now registered to ClearML. ClearML conforms the dataset format for you, and you can easily mix and match datasets – even without changing the code itself – with a few mouse clicks. As you can imagine, this helps tremendously with maintainability and saves time.
If you want to change the dataset – for example, you want to use COCO to train an object detector for household appliances – all that you need to do is modify the dataview you’d like. This can be as simple as choosing a dataset from a drop-down menu, setting your labels, and letting ClearML do all the behind-the-scenes magic for you!
Devil’s Advocate
Now you may say “Hey! That required coding, how is conforming to ClearML’s standard any better than before?”

Deep learning research and development is not a one-time deal. Trying multiple detectors, playing with different datasets, or modifying public repos to your needs is an ongoing process.
Without ClearML dataset management, every repo would need to be converted multiple times to accommodate multiple dataset formats (or vice versa). And this process would be needed for each new SOTA repo your organization wanted to use. It would require you to remember how to parse every dataset format in use; not only is that not scalable, it’s also annoying!
We’re just getting started!
Democratizing deep learning has a long way to go. While academia and research groups break the boundaries of performance on a daily basis, ML engineers around the world, in dynamic, creative companies, are reducing the scaffolding and making the process of applied deep learning easier, simpler, faster, and more fun. At Allegro AI, we’re committed to this mission and we’d like to think that our dataset | code | model encapsulation is just one of the many innovations we are bringing to this space to support this mission.