A Walk in the Park or…a Walk on the Trains Tracks?
There’s a lot to track when training your ML models, and there’s no way around it; reviews and comparisons for best performance are virtually impossible without logging each experiment in detail.
Yes, building models and experimenting with them is exciting work, but let’s agree that all that documentation can be laborious and error-prone – especially when you are essentially doing data entry grunt work, manually, using Excel spreadsheets. Even if you are writing your own documentation code, beyond the initial work you have to maintain that code, and often cut corners on what it tracks.
For many, however, time-consuming manual experiment documentation is finally a thing of the past: Allegro Trains is an open source ML / DL experiment manager, versioning and ML-Ops solution. Among all of its capabilities, it helps machine learning and deep learning scientists document their work effortlessly and flawlessly, with minimal additional coding.
In this post, we’ll explore the value you can get the moment you begin adding Trains to your code. Let’s start at the “hello-world” of deep learning: training mnist classifier.
I’ve chosen to use the pytorch mnist example, but using Keras or TensorFlow would work as well.
Off we go
So here’s our typical scenario: We’ve cloned the code from GitHub, checked to confirm that the data is a good fit to get us started, and reviewed the parameters. All set? Let’s just ship it off to the GPU and, well, stare at the logs…

Well, not so fast…passive observation isn’t particularly productive. For instance:
- What if I want to see the progress of my experiment as real-time graphs?
- What if I want to run multiple experiments and compare them as they progress?
- What if I want to connect between my code and the results?
In the past, it’d be time to open up Excel – or worse, waste time writing code myself that will document my experiments for me. Instead, let’s use Trains’ simple SDK and an easy to-use UI to help us document and organize our research … all with just a code snippet.
Integration in a (very small) nutshell
We’ll start with the heart of the Trains experiment manager: the Task.
from trains import Task task = Task.init(project_name='examples', task_name='pytorch mnist train') logger = task.get_logger()
Here, we are importing the Task object from Trains and then initializing it. Tasks are entities that represent experiments in the Trains system (everything from parameters to metrics are associated with a Task). Then we’ll define a logger to which we’ll eventually write our metrics.
Code Tracking
By initializing a Task, Trains automatically tracks your code; it will identify the git repository you’re running from, the commit ID, and what script was executed. It even stores the git diff, so there’s no need to commit your code!
For those who do not work in git, Trains saves your entire script. If you’re running Jupyter notebooks, Trains converts your notebook into a python script and saves it as a whole.
Trains scans the python environment you’re running from, and will log all the python packages and their versions for experiment recreation later on. Python package logging is important as it can save countless hours trying to run an experiment on another machine, or debugging code that ran just last week, all because NumPy or pandas versions changed.
Lastly, if you’re running from within a docker, Trains will log the docker you ran from.
Hyperparameters
In our code, Hyperparameters are defined using python’s argparser:
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N', help='input batch size for training (default: 64)')
.
.
.
args = parser.parse_args()
Trains automatically captures our argparser when we run
args = parser.parse_args()
If you’re using another method to store hyperparameters (such as a json or XML file) to track hyperparameters, Trains has got you covered (although you might need to write another line of code 😉 ). This is especially important for users of Juypyter notebooks:
task_params = {'num_scatter_samples': 60, 'sin_max_value': 20, 'sin_steps': 30}
task_params = task.connect(task_params)
Model Tracking
We’re ready to save our model, so let’s refer to the pytorch model save method:
if (args.save_model): torch.save(model.state_dict(), os.path.join(gettempdir(), "mnist_cnn.pt"))
But wait, you ask, raising an eyebrow … where’s the Trains-specific code?
Well, that’s exactly what we mean when we say “effortless”. Trains integrates with python hooks behind the scenes so you continue writing the code just as you always did, leaving Trains to do the heavy lifting.
Trains can also manage your models (e.g., upload them to cloud storage or save them locally) as well as storing general purpose artifacts such as files, folders and pandas dataframes (Check out all the options in our artifacts example).
Results
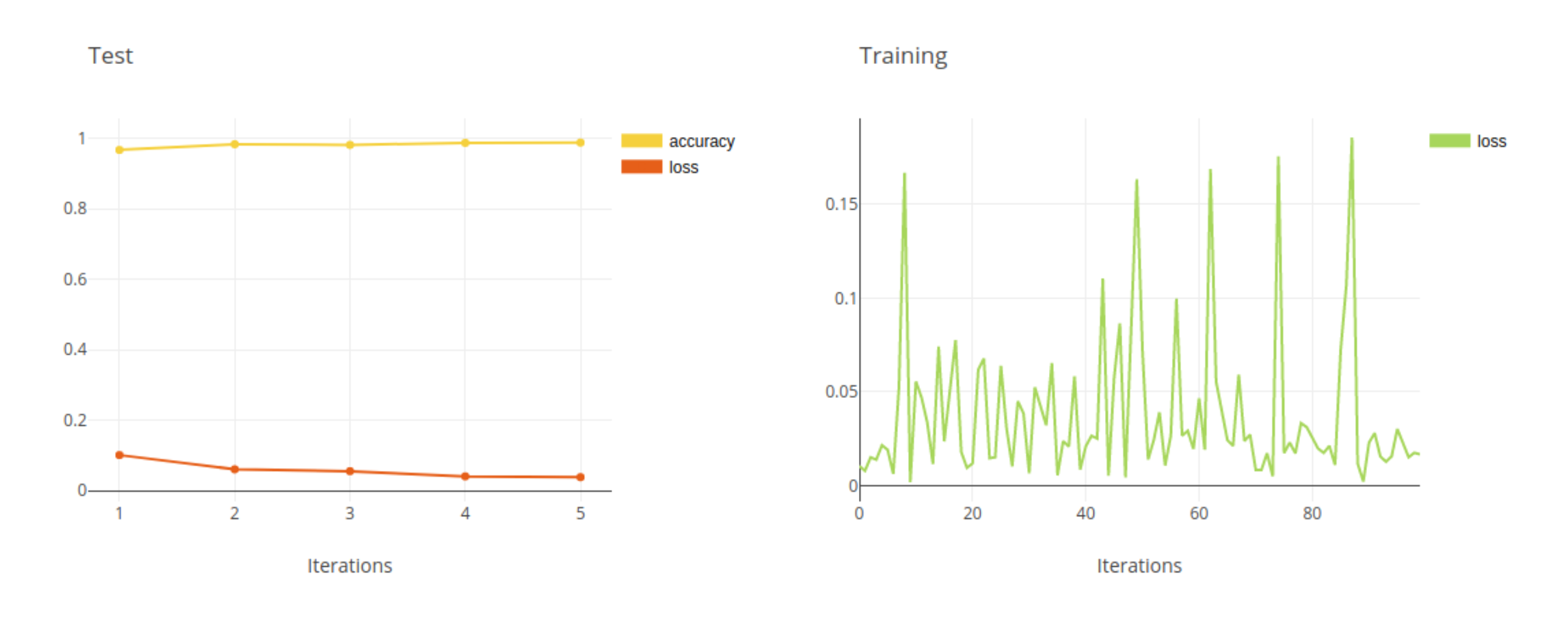
And now, for the main course: Trains automatically captures the console output, whether simply from prints to the console or output from external libraries.
Trains can also capture reported metrics. But just a minute – if we look in the scalars tab, why is it looking pretty empty? That’s because although we can print our Loss and Accuracy, Trains is unable to read your minds to understand that these are important metrics (stay tuned … we are working on mind reading for our next version!).
Users of Tensorboard, TensorboardX or matplotlib are in luck, as Trains will automatically capture anything you report to them. In this example, since we are not using any of these tools, we’ll have to report tracked metrics manually. Inspecting our code, the best place to put these reports is right after we print them out. Let’s add metrics logging:
Train logger:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
logger.report_scalar(title='Training',series='loss',value=loss.item(),iteration=int(100. * batch_idx / len(train_loader)))
Test logger:
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
logger.report_scalar(title='Test',series='loss',value=test_loss,iteration=epoch)
logger.report_scalar(title='Test', series='accuracy', value=correct / len(test_loader.dataset), iteration=epoch)
And the results in the UI:
Experiment Tracking
We promised you experiment tracking, and the time has come. Trains allows you to see all running experiments in a Web UI, and lets you organize experiments by parameters and metrics.
Leaderboards are especially important if you are running more than a couple of experiments, as it quickly becomes a challenge to compare and decipher a dozen or more graphs. To help with that, Trains allows you to create and share customized leaderboards so you can see which are the best performing experiments according to a chosen metric. You can perform a more detailed comparison to find the best one for our specific use case using the Trains comparison feature.
Experiment Comparison
Research work relies on the ability of the researcher to sift through heaps of data points and find the most informative results. For that, Trains includes, as an extra layer on top of the experiments leaderboards, a powerful comparison tool.
For example, once we use Trains’ leaderboard to discover the highest mAP experiments, we can compare the best three. When we look deeper, we notice that, oddly, the best experiment actually does poorly in a category which is important for us. When we do a deep-dive comparison, we can also compare multiple metrics such as run time or number of iterations.
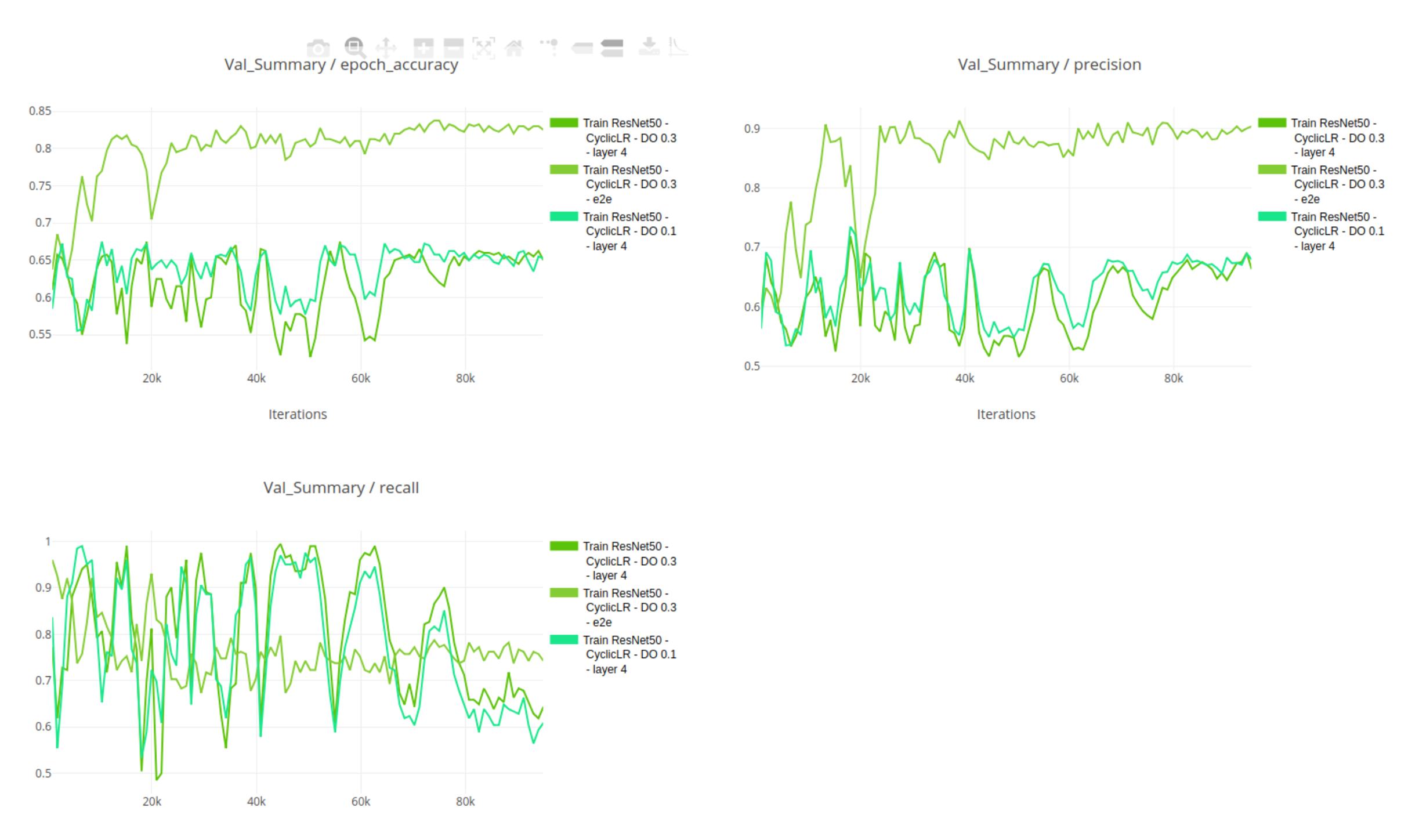
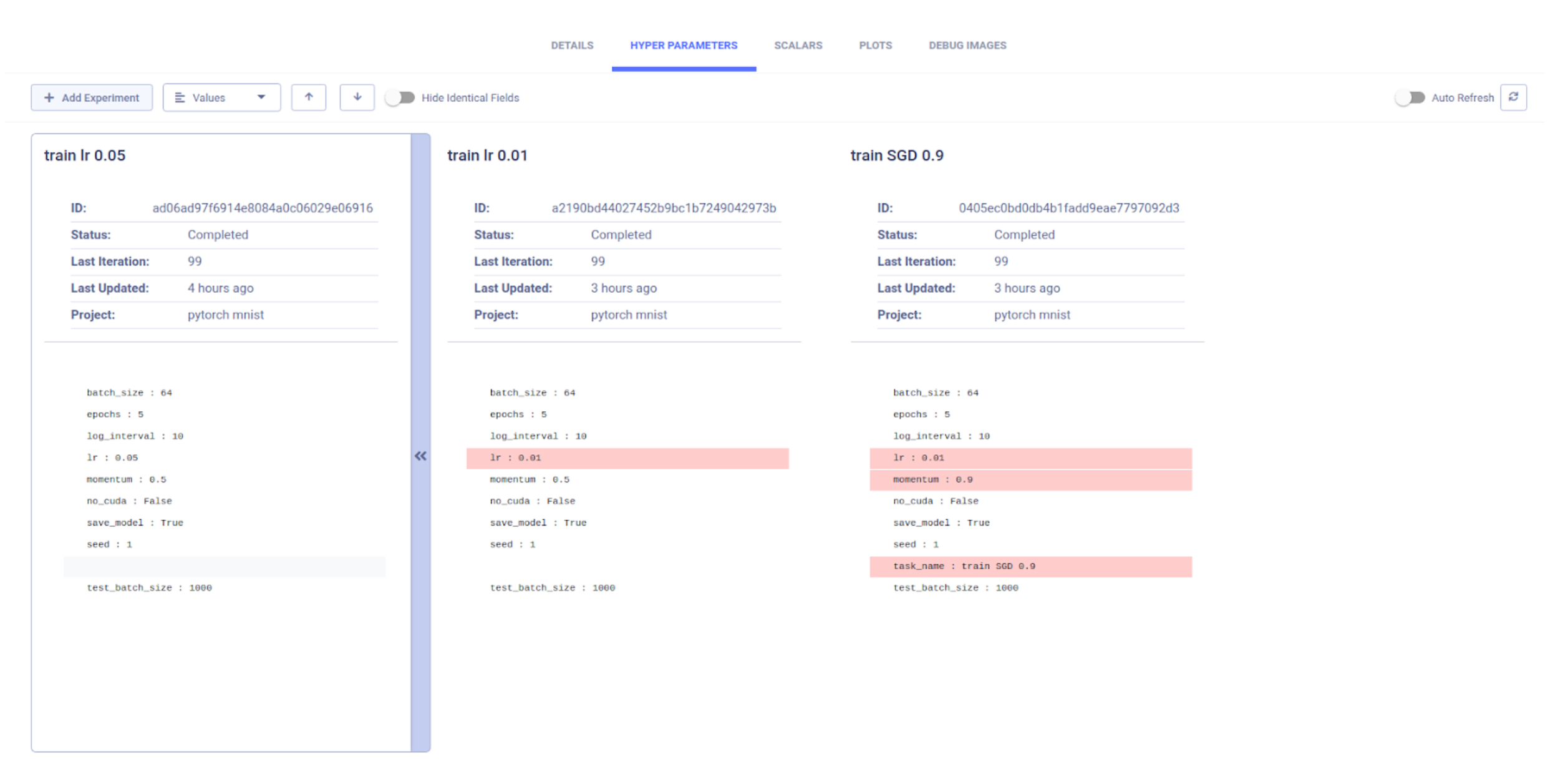
Another aspect of experiment comparison is inputs comparison. Once we’ve chosen the best performing experiment, we naturally want to figure out why it was better than others. Comparing hyper parameters and code versions can give us clues, and since everything is logged automatically, we might find that a parameter that we assumed was insignificant (and we might not even have bothered to log it manually!) has a significant impact on the results.
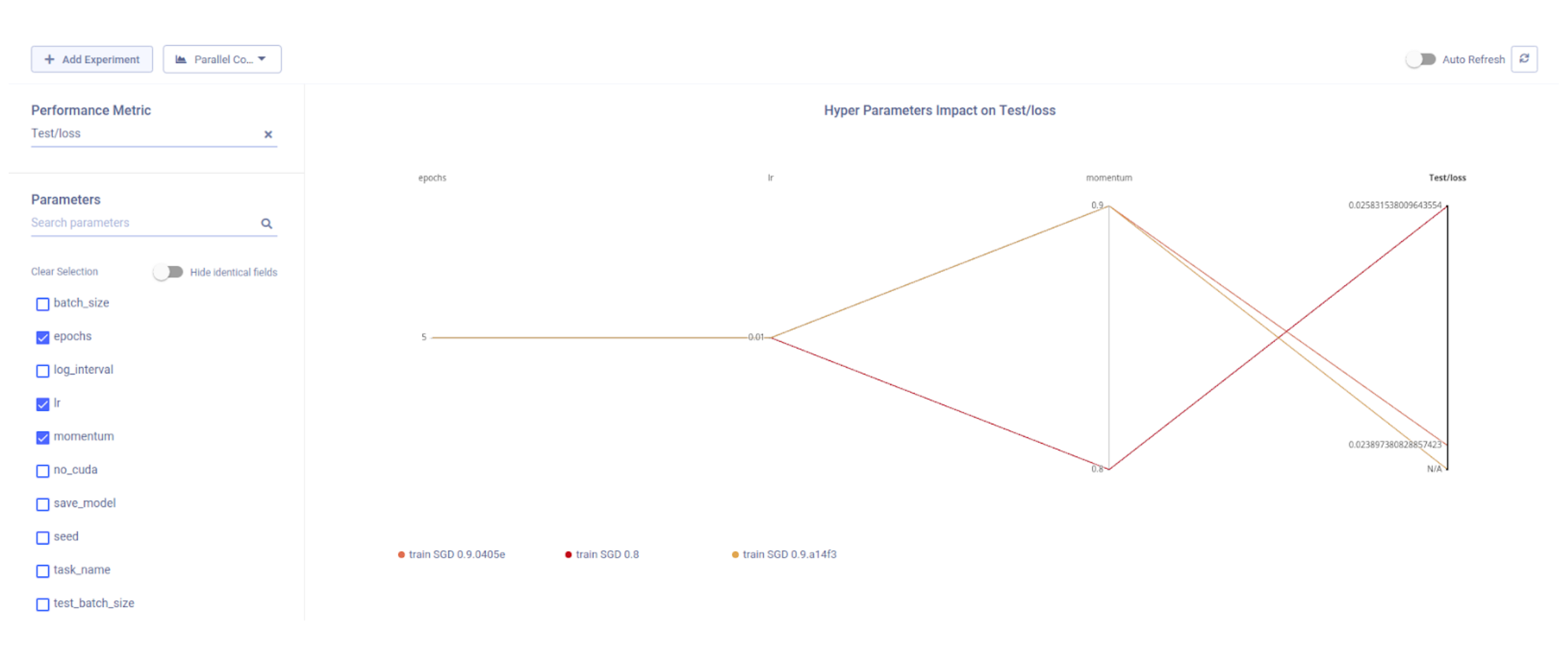
All these goodies (and more!) are just a
pip install trainsaway. You can find a working notebook of the integrated script here, and more resources in our github, documentation page and YouTube channel.
Hey Stranger.
Sorry to tell you that this post refers to an older version of ClearML (which used to be called Trains).
We haven’t updated this yet so some, commands may be different.
As always, if you need any help, feel free to join us with Slack