Originally Published in TDS by Ivan Ralašić – Republished by author approval
Welcoming new animals to the Zoo — model evaluation

Tensorflow Object Detection API (TF OD API) just got even better. Recently, Google released the new version of TF OD API which now supports Tensorflow 2.x. This is a huge improvement that we’ve all been waiting for!
Intro
Recent improvements in object detection (OD) are driven by the widespread adoption of the technology by industry. Car manufacturers use object detection to help vehicles navigate the roads autonomously, doctors use it to improve their diagnosis process, farmers use it to detect various crop diseases… and there are many other use-cases (yet to be discovered) where OD could provide enormous value.
Tensorflow is a deep learning framework that powers many of the state-of-the-art (SOTA) models in natural language processing (NLP), speech synthesis, semantic segmentation, and object detection. TF OD API is an open-sourced collection of object detection models which is used by both the deep learning enthusiasts, and by different experts in the field.
Now when we’ve covered the basic terminology, let’s see what the new TF OD API offers!
● ● ●
New TF OD API
New TF2 OD API introduces eager execution that makes debugging of the object detection models much easier; it also includes new SOTA models that are supported in the TF2 Model Zoo. Good news for Tensorflow 1.x. users is that the new OD API is backward compatible, so you can still use TF1 if you like, although switching to TF2 is highly recommended!
In addition to the SSD (MobileNet/ResNet), Faster R-CNN (ResNet/Inception ResNet), and Mask R-CNN models that were previously available in TF1 Model Zoo, TF2 Model Zoo introduces new SOTA models such as CenterNet, ExtremeNet, and EfficientDet.
Models in the TF2 OD API Model Zoo are pre-trained on the COCO 2017 dataset. The pre-trained models can be useful for out-of-the-box inference if you are interested in categories already included in this dataset, or for initializing your models when training on novel datasets. Using TF OD API models instead of implementing the SOTA models on your own gives you more time to focus on the data, which is another crucial factor in achieving high performance of OD models. However, even if you decide to build the models yourself, TF OD API models present a good performance benchmark!
You can choose from a long list of different models depending on your requirements (speed vs. accuracy):
Models included in the TF2 OD API Model Zoo.
In the previous table, you can see that only the mean COCO mAP metric is given in the table. Although it can be a fairly good orientation for the performance of the model, additional statistics can be useful if you’re interested in how the model performs on objects of different sizes or different types of objects. For instance, if you’re interested in developing your advanced driver-assistance systems (ADAS), you don’t really care if detectors’ ability to detect bananas is bad!
In this blog, we’ll focus on explaining how to perform a detailed evaluation of different pre-trained EfficientDet checkpoints that are readily available in the TF2 Model Zoo.
● ● ●
EfficientDets — SOTA OD models
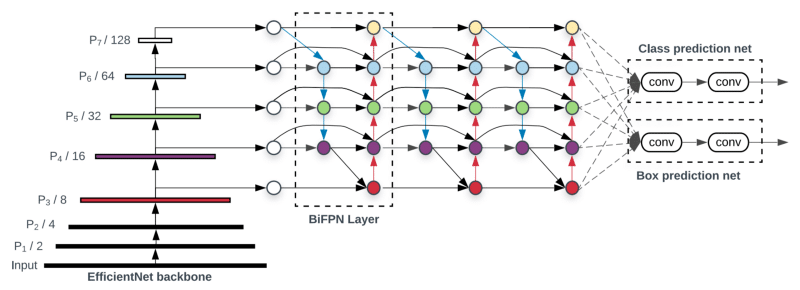
EfficientDet is a single-shot detector fairly similar to the RetinaNet model with several improvements: EfficientNet backbone, weighted bi-directional feature pyramid network (BiFPN), and compound scaling method.
BiFPN is an improved version of the very popular FPN. It learns the weights that represent the importance of different input features, while repeatedly applying top-down and bottom-up multi-scale feature fusion.
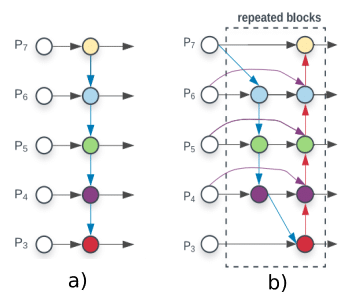
The usual approach for improving the accuracy of the object detection models is to either increase the input image size or to use a bigger backbone network. Instead of operating on a single dimension or limited scaling dimensions, compound scaling jointly scales up the resolution/depth/width for backbone, feature network, and box/class prediction network.
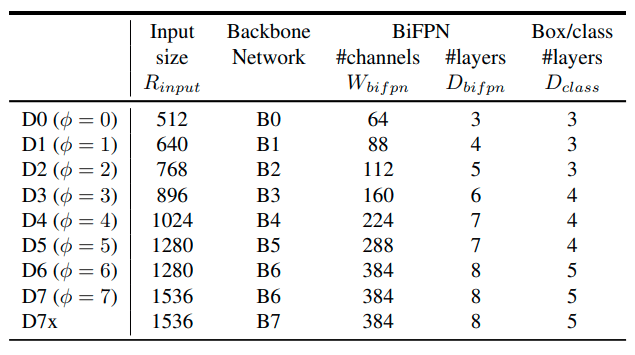
EfficientDet models with different scaling factors are included in the TF2 OD API Model Zoo, and the scaling factor is denoted by the {X} in the name of the model, while the input image resolution is denoted by {RES}x{RES} EfficientDet D{X} {RES}x{RES}.
● ● ●
Evaluation of pre-trained EfficientDet models
We want to perform detailed accuracy comparisons to study the influence of the compound scaling configs on the performance of the network itself. For that reason, we’ve created a Google Colab notebook in which we explain how to perform the evaluation of the models and how to efficiently compare the evaluation results. We’re interested in detailed evaluation statistics including per class and different object size stats.
Unfortunately, TF OD API doesn’t support such stats out of the box. That’s why we created a fork of the TF OD repo and updated the relevant scripts to introduce this functionality following the instructions given in this issue.
In the notebook, we provide instructions on how to setup Tensorflow 2 and the TF2 OD API. We also include scripts that make it easy to download the EfficientDet checkpoints, as well as additional scripts that help you to get the COCO 2017 Val dataset and create tfrecord files that are consumed by the TF OD API in the evaluation phase.
Finally, we modify the pipeline.config files for the EfficientDet checkpoints to prepare everything for sequential evaluation of the 8 EfficientDet checkpoints. TF OD API uses them to configure the training and evaluation process. The schema for the training pipeline can be found in object_detection/protos/pipeline.proto. At a high level, the config file is split into 5 parts:
- The model configuration. This defines what type of model will be trained (i.e., meta-architecture, feature extractor…).
- The train_config, which decides what parameters should be used to train model parameters (i.e., SGD parameters, input preprocessing, and feature extractor initialization values…).
- The eval_config, which determines what set of metrics will be reported for evaluation.
- The train_input_config, which defines what dataset the model should be trained on.
- The eval_input_config, which defines what dataset the model will be evaluated on. Typically this should be different than the training input dataset.
model {
(... Add model config here...)
}
train_config : {
(... Add train_config here...)
}
train_input_reader: {
(... Add train_input configuration here...)
}
eval_config: {
}
eval_input_reader: {
(... Add eval_input configuration here...)
}
We’re only interested in the eval_config and eval_input_config parts of the config file. Take a closer look at this cell in the Google Colab for more details on how we set up the eval parameters. Two additional flags that are not enabled out of the box in the TF OD API are include_metrics_per_category and all_metrics_per_category. After applying the patch given in the Colab notebook, when set to true these two enable detailed statistics (per category and size) that we’re interested in!
● ● ●
ClearML — efficient experiment management
To be able to efficiently compare the model evaluations, we use an open-sourced experiment management tool called ClearML. It’s very easy to integrate it into your code and it enables a load of different functionality out of the box. It can be used as an alternative to Tensorboard for visualizing experiment results.
![]()
Main script in the OD API is object_detection/model_main_tf2.py. It handles both the training and the eval stage. We created a small script that calls model_main_tf2.py in a loop to evaluate all EfficientDet checkpoints.
To integrate ClearML experiment management into the evaluation script, we had to add 2 (+1) lines of code. In the model_main_tf2.py script we’ve added these lines:
from clearml import Task task = Task.init(project_name="NAME_OF_THE_PROJECT", task_name="NAME_OF_THE_TASK") # OPTIONAL - logs the pipeline.config into the clearml dashboard task.connect_configuration(FLAGS.pipeline_config_path)
and ClearML automatically starts to log numerous things for you. You can find a comprehensive list of features here.
● ● ●
Comparing different EfficientDet models
On this link, you can find the results of the evaluation of 8 EfficientDet models included in the TF2 OD API. We’ve named the experiments as efficientdet_d{X}_coco17_tpu-32 where {x} denotes the compound scaling factor for the EfficientDet model. You’ll get the same results if you run the sample Colab notebook, and your experiments will show up on the demo ClearML server.
In this section, we’ll show you how to efficiently compare different models and verify their performance on the evaluation dataset. We’re using COCO 2017 Val dataset since it’s a standard dataset for the evaluation of object detection models in the TF OD API.
We’re interested in the COCO Object Detection model evaluation metrics. Press here to see experiments’ results. This page contains graphs with all the metrics that we’re interested in.
We can first take a look at the DetectionBoxes_Precision plot which contains the average precision metric for all the categories in the dataset. The value of the mAP metric corresponds to the mAP metric reported in the table in the TF2 Model Zoo.
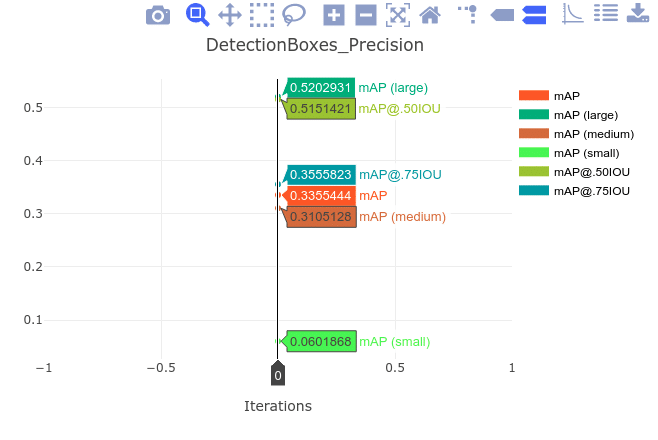
Thanks to the patch we applied to the pycocotools, we can also get the per-category mAP metrics. Since there are 90 categories in the COCO dataset, we want to know the contribution of each category to the mean accuracy. This way we get more granular insight into the performance of the evaluated model. For example, you might be interested in how the model performs only for small objects in a certain category. From the aggregated statistics, it’s impossible to get such insights, while the proposed patch enables this!
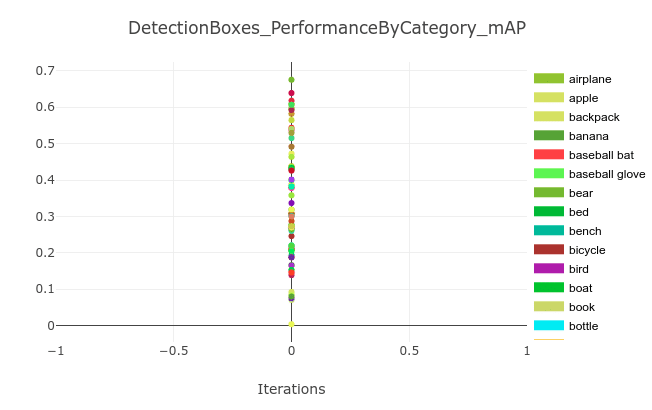
We also use ClearML’s capability to compare multiple experiments. The experiment comparison shows all the differences between the models. We can first get a detailed scalar and plot comparison of the relevant stats. In our example, we’ll compare the performance of EfficientDet D0, D1, and D2 models. Obviously, compound scaling positively influences the performance of the models.
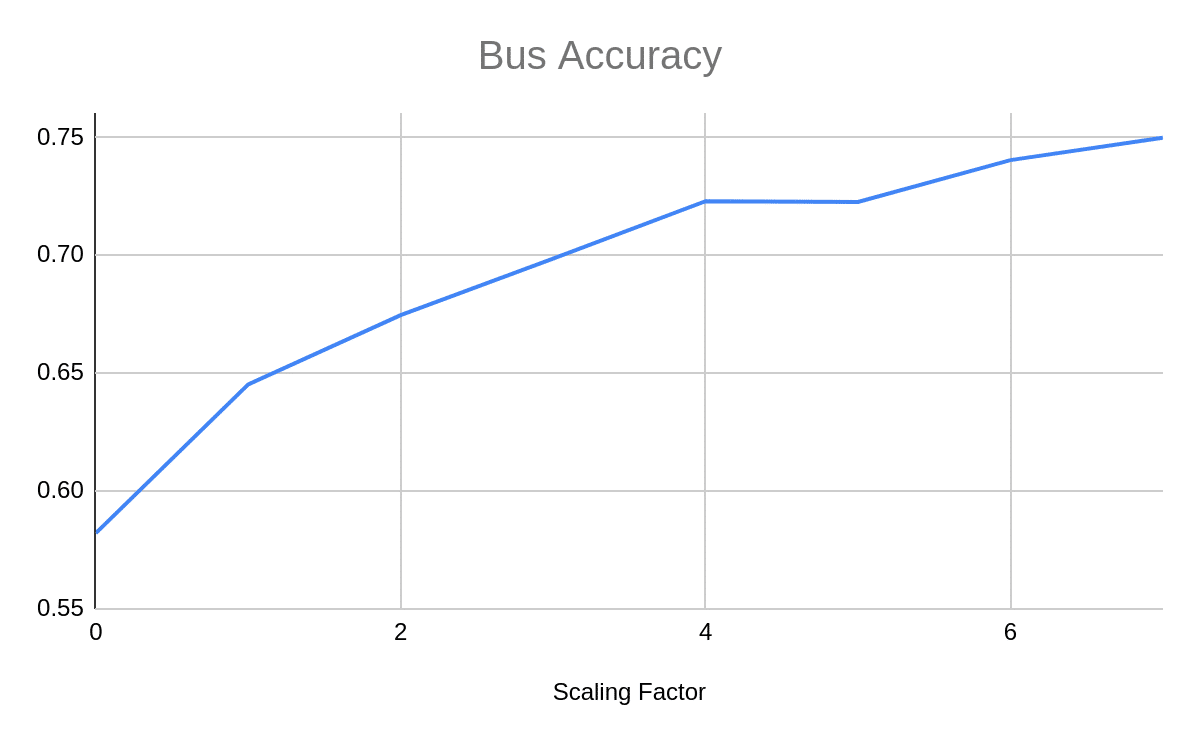
One of the additional benefits of having per category stats is that you can analyze the influence of compound scaling factors on the accuracy of a certain class of interest. For example, if you’re interested in detecting buses in a surveillance video, you can analyze the graph that shows mAP performance for the bus category vs. compound scaling factor of the EfficientDet model. This helps decide which model to use, and where the sweet spot is between performance and computational complexity!
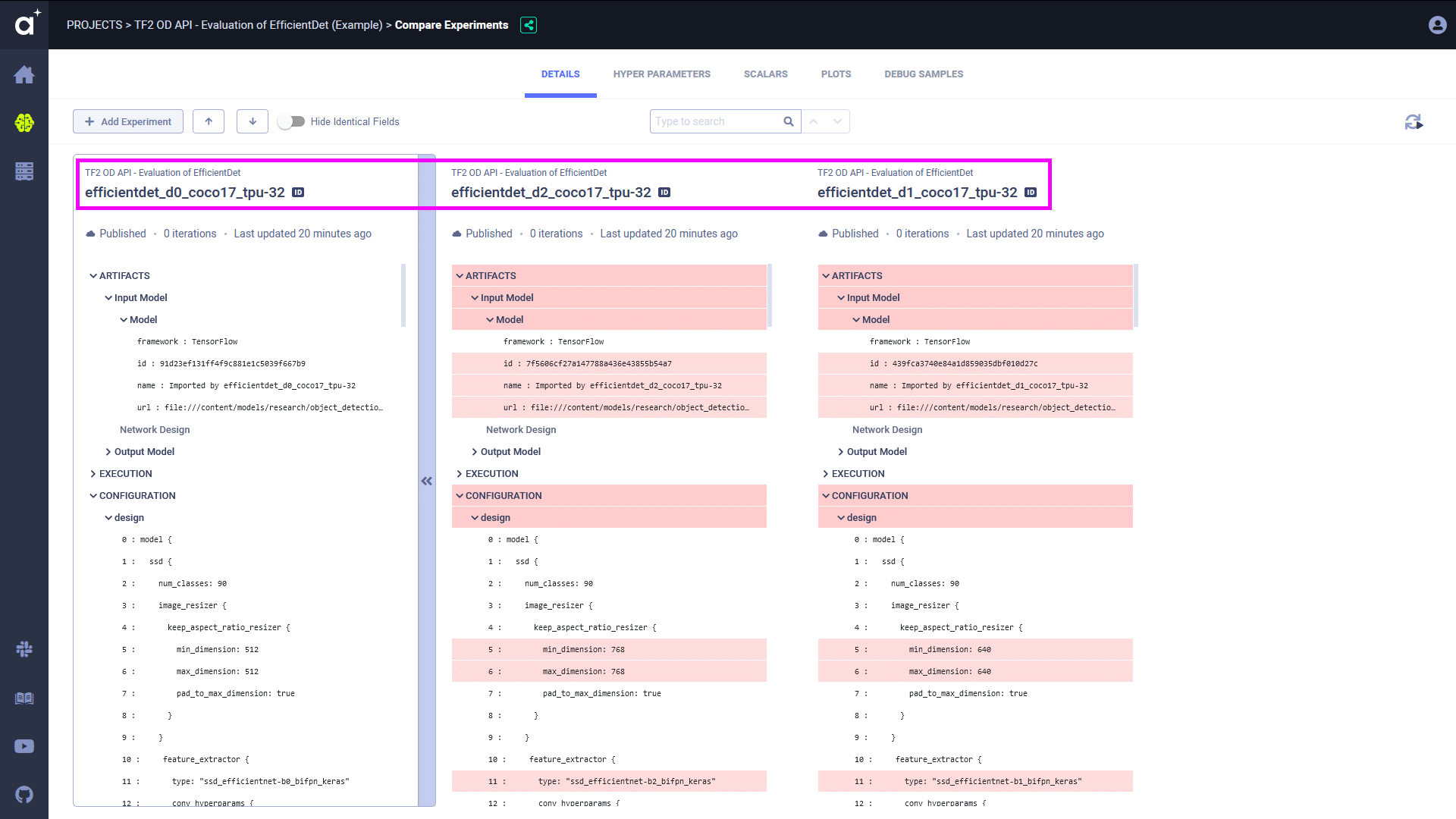
One of the interesting things that you can also compare is the model configuration file pipeline.config. You can see that the basic difference between the EfficientDet models is in the dimensions of the input image and the number/depth of filters, as discussed earlier.
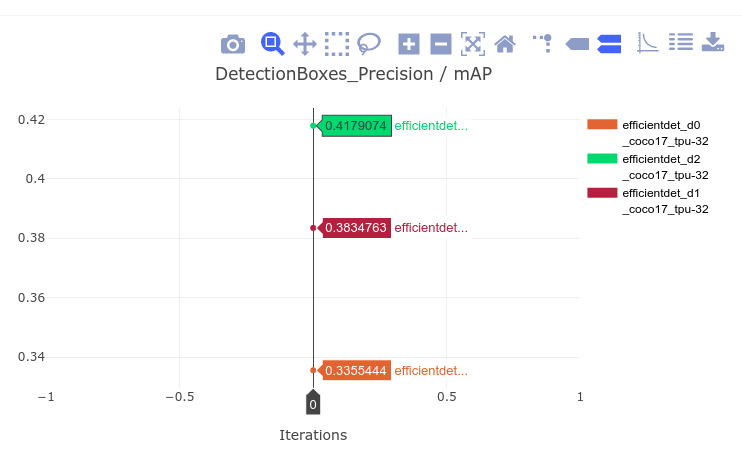
The next plot contains the mAP values for 3 EfficientDet models. There is an obvious benefit in increasing the input image resolution, as well as increasing the number of filters in the model. While the D0 model achieves 33.55% mAP, the D2 model outperforms it and it achieves 41.79% mAP. You can also try out to perform per-class comparisons, comparison of other EfficientDet models, or whatever you find interesting for your application.
● ● ●
How is TF OD API used to improve construction site safety?
Forsight is an early-stage startup and our mission is to turn construction sites into safe environments for workers. Forsight uses computer vision and machine learning, processing real-time CCTV footage, to help safety engineers monitor the proper use of personal protection equipment (PPE) to keep sites safe and secure.
Our construction site monitoring pipeline is built on top of the TF OD API and features include PPE detection and monitoring, social distance tracking, virtual geofence monitoring, no-park zone monitoring, and fire detection. At Forsight, we also use ClearML to keep track of our experiments, share them between team members, and log everything so we can reproduce it.

As the COVID-19 pandemic continues, construction projects around the world are actively looking for ways to restart or keep projects going while keeping workers safe. Computer vision and machine learning can help construction managers ensure that their construction sites are safe. We built a real-time monitoring pipeline that tracks social distancing adherence between workers.

In addition to the new, invisible threat of COVID there are some age-old dangers that all construction workers face each day, notably, the ‘Fatal Four’: falls, struck by objects, caught in or between and electrocution hazards. Ensuring that workers wear their PPE is crucial for the overall safety of a construction site. TF OD API is a great starting point towards building an autonomous PPE monitoring pipeline. Our next blog will touch on how to train a basic helmet detector using the new TF OD API.

Some areas of a construction site are more dangerous than others. Creating virtual geofence areas and monitoring them using CCTV cameras adds huge value to the construction managers since they can focus on other tasks while being aware of any geofence breaches happening on their site. Moreover, geofencing can be easily extended to monitoring access to machines and heavy equipment.

● ● ●
Conclusion
In this blog, we have discussed the benefits of using the new TF2 OD API. We have shown how to efficiently evaluate pre-trained OD models that are readily available in the TF2 OD API Model Zoo. We have also shown how to use ClearML as an efficient experiment management solution that enables powerful insights and stats. Finally, we’ve shown some real-world applications of object detection in a construction environment.
This blog is the first blog in the series of blogs that provide instructions and advice on using TF2 OD API. In the next blog, we’ll show how to train a custom object detector that enables you to detect workers wearing their PPE. Please follow us for more hands-on tutorials! Also, feel free to reach out to us if you have any questions or comments!
● ● ●
[1] “Speed/accuracy trade-offs for modern convolutional object detectors.”
Huang J, Rathod V, Sun C, Zhu M, Korattikara A, Fathi A, Fischer I, Wojna Z,
Song Y, Guadarrama S, Murphy K, CVPR 2017
[2] TensorFlow Object Detection API, https://github.com/tensorflow/models/tree/master/research/object_detection
[3] “EfficientDet: Scalable and Efficient Object Detection” Mingxing Tan, Ruoming Pang, Quoc V. Le, https://arxiv.org/abs/1911.09070
[4] “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks” Mingxing Tan and Quoc V. Le, 2019, https://arxiv.org/abs/1905.11946