Originally written by Henok Yemam on TDS (link)- Republished by author approval.
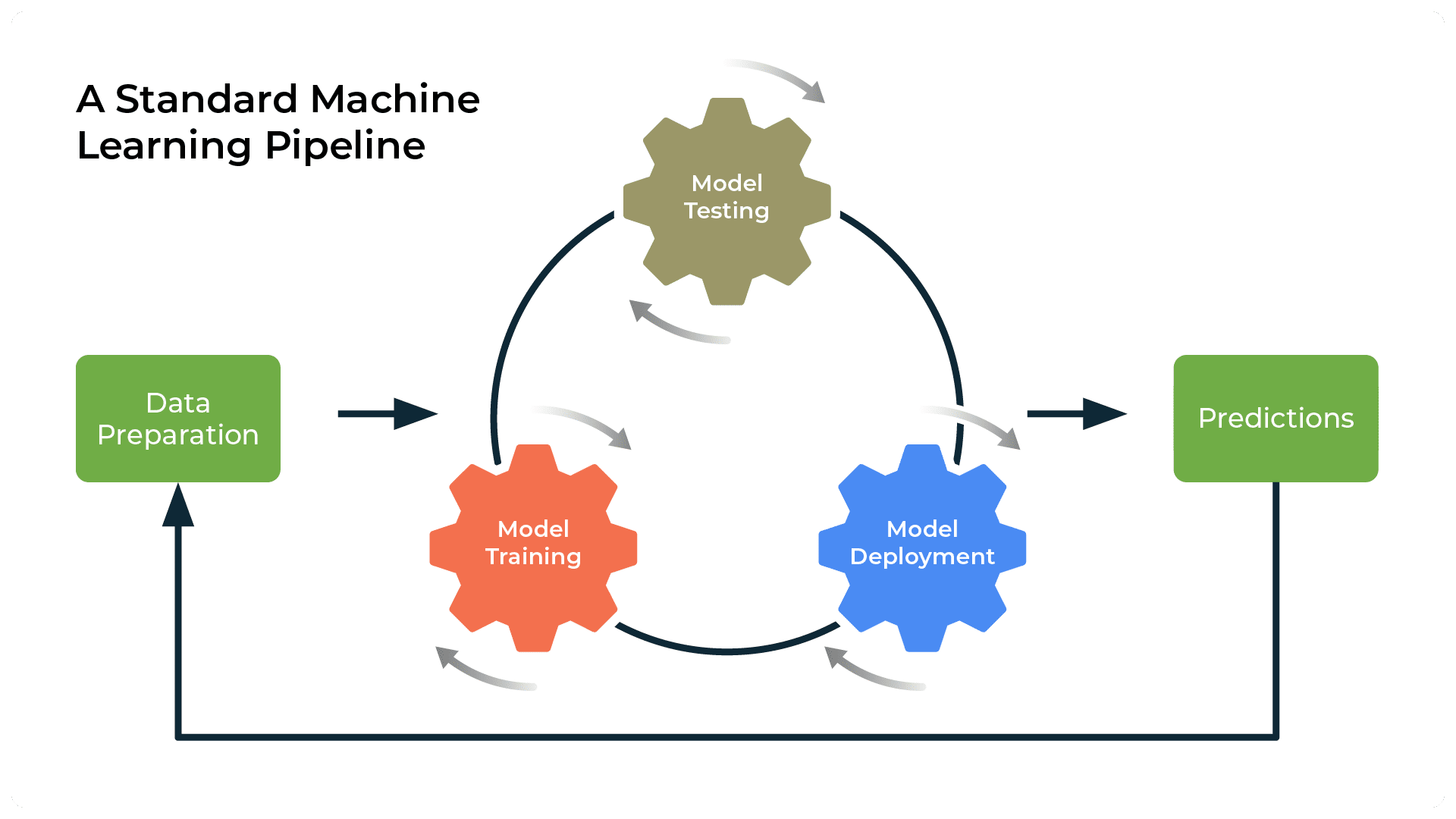
The infamous data science workflow with interconnected circles of data acquisition, wrangling, analysis, and reporting understates the multi-connectivity and non-linearity of these components. The same is true for machine learning and deep learning workflows. I understand the need for oversimplification is expedient in presentations and executive summaries. However, it may paint unrealistic pictures, hide the intricacies of ML development and conceal the realities of the mess. This brings me to the tools of the trade or more commonly referred as the infrastructure of artificial intelligence which is the vehicle under which all libraries, experimentations, designs and creative minds meet. These humble infrastructures tend to be overlooked and underappreciated but their glaring importance can’t be overstated. I will explain a couple of these very tools that could be used in tandem to improve your workflow, accountability of data exploration, and lower the time and resources to go from proof-of-concept (POC) to deployment.
Open-Source Software
Before you are on the stage with a turtleneck shirt and casual blue jeans to reveal your data-intensive breakthrough product, the first step is to choose software to tackle the complex terrains of machine learning. Lucky for you, there are excellent open-software platforms such as Apache Spark, Jupyter, TensorFlow, PostgreSQL, and many more to get you started. The recent addition to my list is Allegro Trains which I am a huge proponent of. As a working data scientist, I have five criteria before choosing to use open-source software. These are:
- Availability and ease of use for POC.
- Reproducibility and collaboration.
- Cross-platform compatibility.
- Resource optimization.
- Productivity boost relative to the learning rate.
In the spirits of these criteria, let’s explore Jupyter and Trains.
Jupyter and Allegro Trains
Jupyter notebook is the de facto gateway to interactive computing for aspiring data scientists and engineers. It offers quick feedback in the form of errors or visual displays and allows users to test out their rudimentary ideas. It’s undoubtedly the perfect tool for POC in addition to being language agnostic and offering text through Markdown cells. Jupyter Lab adds modularity to the notebooks so you are not opening multiple tabs with each notebook. There is also JupyterHub which allows multiple users to share notebooks. These are all great platforms to get some hands-on experience.
The problem comes when you are tackling complex projects where a large number of iterations and experimentations, crucial code and resource optimizations, versioning and collaboration, and data integration and deployment are needed. These are the bottlenecks of bringing data-driven products to the market. As a result, AI architectures that incorporate these features in addition to the five criteria above become a necessity to accelerate R&D to market stages with faster ROI.
Why Allegro Trains?
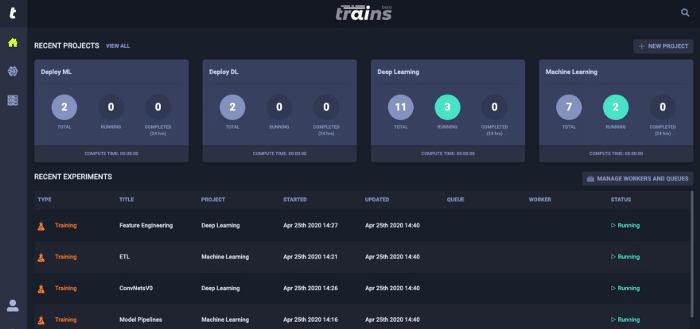
Take a look at the dummy four projects in figure 1 and imagine if you were running these projects on Jupyter, the level of difficulty to keep the purpose of each notebook quickly becomes a task of its own. You could solve this issue by setting up a git repository to handle your versioning needs and manage your progress. You could also install a memory profiler to manage your resource allocation to each task. What about automating your ML models? You could explore the growing list of AutoML. If you are starting to realize that your ML project complexity is rising with each step to completion, then you are not the only one. This is a common problem and the solution should be addressed with a singular project hub. This is precisely why Allegro Trains was developed.
Allegro Trains puts a stop to these all-too-common infrastructure problems. Instead of patching your problems with countless modules, it’s time to bring maturity to ML with an encompassing solution. Trains provides a simple MLOps and AI infrastructure solution to speed up machine/deep learning projects from R&D to deployment. It allows data professionals to take charge of implementing creative insights without the need to worry about messy notebooks, interruption to solve versioning issues, model comparisons, automatic logging, performance tracking, and even CPU/GPU/IO resource allocations. In short, it meets my five-criterion for using open-source software. It also has AutoML to expedite experimentation and the capability to terminate resource-intensive or underperforming tasks from the Web UI.
I would like to leave you with this last remark. The ability to use open-platforms in tandem to bring your exciting ideas and R&D to market has become a matter of simple installations. Jupyter is there for your needs of exploration and ClearML tracks your every progress from POC to optimization and collaboration across teams to deployment with Trains Server.