Tools, tips and best practices for today’s reality
Written by Dan Malowany, Head of Deep Learning Research, Allegro AI
The COVID-19 crisis caught most of us by surprise. Like virtually every business, in every sector, our company was caught unawares as to suddenly move our entire data science team to their den tables, guest rooms and hastily assembled home offices. In the recent years as the Head of Deep Learning Research at Allegro AI, I did have some experience with the challenge of working with a remote team, as I managed both local and remote data science researchers. I’ve tried out and adopted some core tools and best practices to make working remotely and managing remote teams easier and efficient. In this short blog, I will share with you some of my top tips, which I hope will help you get through this crisis as painlessly as possible…getting to know tools that can (and should) stay with you even when you return to the office.
Team Communication
Roadmap & Tasks
The main method to synchronize the team on both short-term and long-term goals, is to leverage a project management tool. Sharing a clear roadmap and defining tasks enables all team members to work separately, but in parallel, with these common goals in mind. Whether you choose Jira, Trello, Asana, or a similar solution, pick a tool that enables you to:
- Create a roadmap : split your high-level goals into tasks and subtasks, and set a time frame (beginning and end) to each task
- Appoint a data scientist to each subtask
- Comment and share files on each subtask
- Change priority and schedule with time
Personally, I use Jira. In their next-gen project, you can choose either a Kanban or Scrum template. As I focus on research, I found Scrum sprints to be less of a natural fit; I prefer to work with the Kanban template that has a roadmap tab built in. I split the team goals into epics, and appoint each researcher to an epic. On the project board, I also add a Priority column to which I push tasks when urgent issues arise.
Communication Hierarchy
It’s a no-brainer that continuous communication between team members is essential for effective teamwork. But how you manage this dynamic can get tricky: On one hand, you want the team to communicate and brainstorm as much as needed. On the other, non-stop messages, beeps and pop-ups disrupt and distract, and returning one’s attention to solving the problem at hand can take time. I found that setting a hierarchy of communication steps helps keep the right balance. For instance:
- Use Slack channels and/or WhatsApp groups for ongoing communication between team members. Set Slack to allow notification only for direct messages and name mentioning; this helps avoid unwanted distractions and loss of focus due to the non-stop waterfall of messages in typical Slack channels.
- Help others embrace the above paradigm — when possible, only initiate a Slack or WhatsApp direct message for one-on-one discussions.
- Plan daily phone calls to more comprehensively discuss open issues, plan the upcoming day, and target urgent challenges.
- For the highest-level topics, run a weekly video conference ( we use Zoom) to update each other on roadmap status, brainstorm open issues, and plan the next week.
Keep in mind that as team members are working from home, schedules may need to be flexible; it’s not always clear when someone is available for a work-related discussion. Using Slack enables us to see who is connected, but this technique is, of course, not a replacement for trying to roughly define a schedule, just like at the office, during which all team members are expected to be working.
Data Science Team Collaboration
Now that each team member knows his tasks and the communication channels are clear, we need to make sure the team can collaborate effectively.
First, as we are data scientists, we obviously need to make sure all team members have easy access to the data from home. Any secure shared cloud storage will do, whether it is Amazon AWS, Google storage or Microsoft Azure. On-premise storage with VPN access is also possible, but can make things a bit more complicated or add latency. We chose to work with secure AWS buckets. We set up different buckets for different projects, so the access is defined and limited to whoever needs it.
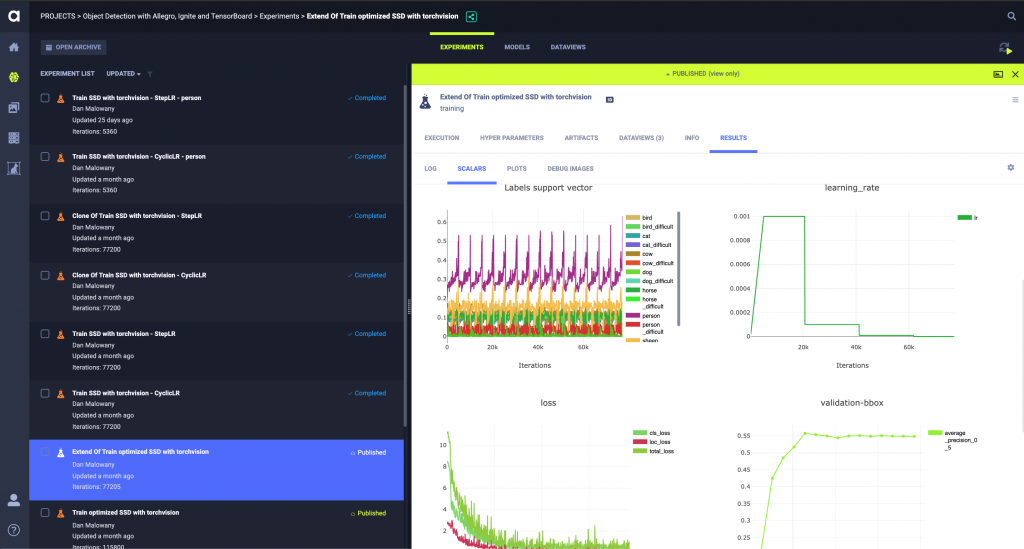
Next, I recommend organizing your work into projects. Let me explain: A project doesn’t necessarily mean a completely unique use case. It can be the same task for a different client, or the same client with different model architecture we want to check, or even same data and same codebase, but for a different team (for example, the QA team). We obviously need a web interface where the entire team can create these projects and organize their work in a productive manner. We use the open source Allegro Trains experiment manager. You can read more about the overall concepts of remote working in Allegro Trains here. Once the team sets up trains-server in a location that can be accessed by all team members, each experiment (script execution) is logged under a defined project. If needed, experiments can be painlessly and instantly moved from one project to another.
It is important to note that with the pressure to keep productivity up in this new reality, the heavy integration overhead required to start working with a new experiment manager is simply not an option. Especially as we are all working from separate locations, we don’t have the luxury of learning to use a new tool and training all team members. That is why the “automagical” features of Allegro Trains are so appealing — you only need to add two lines of code to the beginning of your main script, and Allegro Trains creates and updates logs on each experiment, recording all relevant information:
- Execution — All the execution data: git repository, branch, commit id, uncommitted changes and all used python packages, and their specific versions at time of execution. This ensures that it is possible to reproduce the experiment at any time. We are all familiar with cases where a package version changes and our script simply doesn’t work anymore. This feature helps us avoid having to troubleshoot such frustrating cases.
- Hyper parameters — All ArgParser parameters are automatically logged by Allegro Trains. That enables comparing different experiments and identifying the parameter that causes superior results. It also enables performing automatic hyper parameter optimization using trains-agent.
- Artifacts — All loaded models and snapshot models are automatically saved in this section. Allegro Trains also enable saving additional files on the experiment in this field, like the configuration files used in the experiment and data pre-processing/post-processing information.
- Results — All experiment’s results are logged here. All reports to the console, TensorBoard and matplotlib are aggregated here and can be accessed for later analysis and experiment comparison. In addition, Allegro Trains automatically monitors CPU, GPU and computer information along the course of the experiment, and shows the related graphs here. This important tool helps to identify problems such as memory leaks, lack of hard drive space, low GPU utilization, and more.
Now that all experiments are logged in Allegro Trains’ webapp, each team member can share his work with the other teammates. This is a powerful tool for team collaboration, which enables:
- Online continuous sharing of what each team member is doing
- Choosing a metric for comparison, and creating a leaderboard ranking all the team’s experiments
- Visually brainstorming the results, including, if needed, help from other team members
- Sharing an experiment that performed well on one use case and then easily applying it to another use case
Data Science Infrastructure
The final step to working effectively from home is to have the data science infrastructure ready to support all teamwork. When working remotely, most team members use their laptops or home PCs — machines that are not necessarily suited for deep learning tasks. Meanwhile, all the higher-powered computers in the office are left untouched and available. Installing trains-agent on each computer with a GPU, whether it is an office computer or cloud machine, will make it available to all team members to use.
The installation of trains-agent is as simple as:
pip install trains-agentOnce installed, you execute a simple configuration command and you are good to go:
trains-agent initNow that we have a pool of machines running trains-agent and registered into our trains-server, we need to decide how to allocate the machines to team members. I usually choose to divide the machines between the team members based on their task in the upcoming week. In our weekly meeting we discuss the requests for resources from all team members and the urgency of their tasks. Once the resources allocation is agreed upon, each computer is set to listen to a specific queue designated for each team member by running:
trains-agent daemon --queue dan_queueLast but not least: We all know that setting up Cuda and Cudnn on each computer can be a real hassle, especially as different framework versions require different Cuda versions. trains-agent makes this issue irrelevant; you just choose in the task (in the webapp or in the code), which docker from dockerhub to use, and trains-agent will take care of the rest. For example, just state that the requested docker is “nvidia/cuda:10.0-cudnn7-runtime” and your experiment will be executed within this docker. This is also powerful if we want all team members to share the same environment, so we won’t have contradictory requirements between different pieces of code. Just create your own docker, and make sure all team members set it in Allegro Trains.
Summary
Though these are challenging times, we can all use this time to learn and adopt new tools and work methodologies … as long as they are intuitive and involve a very shallow learning curve. This blog is my effort to help the data science community in this crisis, and I hope you find my tips helpful. There are plenty of useful tools out there that can help us increase our productivity, especially in a remote work environment; a small investment in choosing the right ones will yield significant savings in time and frustration. It’s no exaggeration to say that effective selection and use of these tools are crucial to coping with the COVID-19 crisis ‒ but will be just as helpful when we get back to work in the office.